2023-07-11: AI weights, Learning eBPF workshop, tracepusher for CI/CD Observability, Cost efficiency with Kepler and krr, KubeShark, Flux 2.0.0¶
Thanks for reading the web version, you can subscribe to the Ops In Dev newsletter to receive it in your mail inbox.
👋 Hey, lovely to see you again¶
Hope you are having a great time wherever you are reading this newsletter and finding time to relax and take a vacation. In Germany, summer has reached 34 degrees Celsius (93.2 Fahrenheit), making my brain melt. Things have been quite busy in June and July - Cloudland 2023 was a fantastic community event where we learned AI, eBPF, and Observability together in birds-of-a-feather sessions workshops and talks. My new talk "Observability for Efficient DevSecOps Pipelines" uses a slow CI/CD pipeline that can be analyzed and optimized step-by-step. tracepusher is one of many great tools mentioned for pipeline tracing, next to discussions about better cost efficiency, optimizing resource usage, leveraging cloud-native technology such as eBPF, and how AI can help. A culmination of my learnings shared in this newsletter with you :)
🌱 The Inner Dev learning ...¶
This month's learning list:
- AI weights are not open "source" article by Sid Sijbrandij.
- Debugging Production: eBPF Chaos article on InfoQ.com - eBPF use cases for production, and how to verify reliability with chaos engineering by Michael Friedrich, published June 2023.
🐝 The Inner Dev learning eBPF¶
For Cloudland 2023, I created a new workshop "Learning eBPF for better Observability" with new exercises. Thanks to Liz Rice's great book "Learning eBPF", the workshop added more challenges to the exercises. The workshop project provides a Lima VM (macOS), Vagrant environment, or standalone Ansible role to provision a Ubuntu 23 VM with the required build tools and git clones. The slides guide you through the workshop environment, and is structured into the following learning path way:
- eBPF first steps (Learning strategy, bcc: trace evecve, bcc discussion, bpftrace, bpftrace: open calls, bpftrace use cases)
- eBPF development (languages, architecture, CO-RE, eBPF Verifier, Kernel code: count packets with XDP, maps, load kernel programs)
- Development libraries (XDP with Go, XDP with Rust)
- eBPF for Observability (eBPF exporter for Prometheus, Prometheus metrics, OpenTelemetry, Profiling, Kubernetes with Coroot)
- Additional content: eBPF for SRE&DevOps, eBPF for Security, eBPF for Everyone; Automation, CI/CD, DevSecOps
All learning resources are documented on o11y.love.
Quick wins:
- Cilium CNI: A Comprehensive Deep Dive Guide for Networking and Security Enthusiasts!
- Exploring eBPF and XDP provides an example walkthrough for handling ingress traffic.
- Isovalent lab: Getting Started with Tetragon
🤖 The Inner Dev learning AI/ML¶
Stack Overflow said "Self-healing code is the future of software development" and I could not agree more. Not only in times when code and architecture complexity increases - the entire DevOps lifecycle evolved fast. Dependabot/Renovate help with dependency automation, and drift detection in GitOps workflows help prevent deployment problems. A little help from AI with self-healing in every stage of the DevOps lifecycle is the next step.
OpenAI announced the Code Interpreter plugin alpha, an experimental ChatGPT-4 model with a working Python interpreter in a sandboxed execution environment, and spherical disk space. Will be interesting to see how code execution helps with calculations, generating graph plots from data arrays, or even creating ephemeral remote development workspaces in some way with AI ... This Twitter thread dives into more examples for Code Interpreter usage.
My colleague Gabriel Engel asked me to review a new blog post about GPU-enabled GitLab SaaS Runners to empower ModelOps and HPC workloads. At first, I did not understand how GitLab Runners would be able to access graphical processing units (GPUs) for training machine learning models. After some research, I found this great article about "How Docker Runs Machine Learning on NVIDIA GPUs, AWS Inferentia, and Other Hardware AI Accelerators". It helped to understand that NVIDIA GPU hardware on a Linux host can be accessed with installing the CUDA drivers (NVIDIA container toolkit) into a Docker image, and then use the image in GitLab CI/CD pipeline jobs. The blog post provides hands-on examples for training the first models in CI/CD, which is fascinating at its best - looking behind the curtain of how technology is built (similar to how I want to understand eBPF for innovation and risks).
I'm also investing time into learning with AI-assisted MR summaries when someone sends a review request, and learning a new programming language using code suggestions, available with GitLab Duo. My other AI research topics include cost efficiency and observability with AI, and pipeline efficiency to fix failing jobs fast with a little help from AI.
Quick wins:
- Free Coursera course: Generative AI with Large Language Models by DeepLearning.ai and AWS.
- Implementing Generative Agent With Local LLM, Guidance, and Langchain
- SkyPilot: Run LLMs, AI, and Batch jobs on any cloud. Get maximum savings, highest GPU availability, and managed execution—all with a simple interface.
👁️ Observability¶
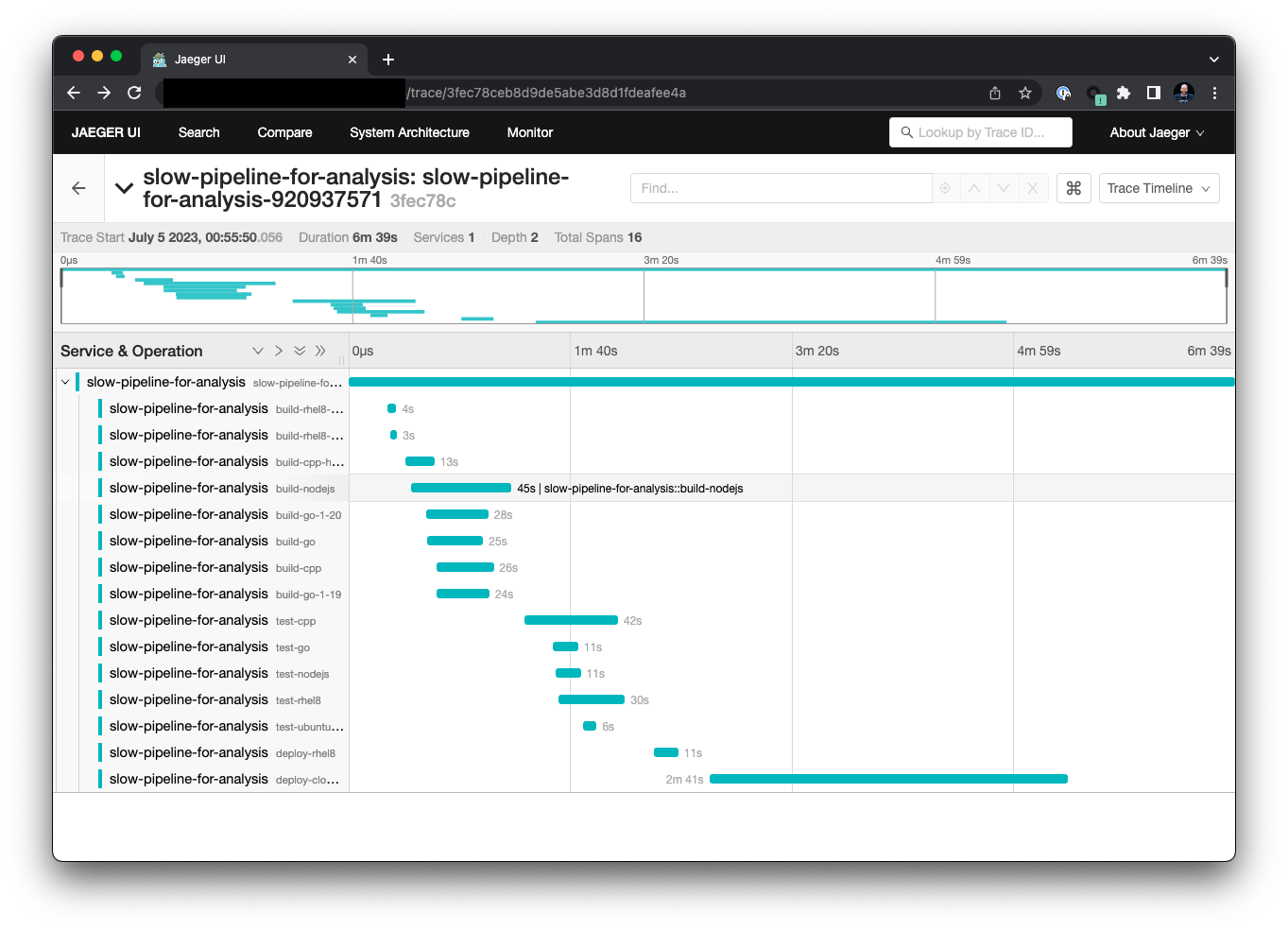
tracepusher is a new Open Source project that provides a Python script to send traces to OpenTelemetry. The script can be run standalone on the command-line or integrated into GitLab CI/CD pipelines. The CI/CD configuration needs to be extended with a preparation job to generate a unique trace ID for the pipeline run, and consecutive before_script and after_script default definitions for all jobs to generate span IDs, and emit the trace span to OpenTelemetry with the tracepusher script, with a post pipeline job that finalizes the trace.
You can create a quick demo setup with an OpenTelemetry collector that accepts HTTP messages using this project which docker-compose. You can then follow my public learning curve implementing tracepusher into the slow pipeline project in this MR. I also created upstream pull requests and issues, including emphasis on the CI-tagged image, jobs that specify a custom image, before_script/after_script override problem workarounds and Jobs with needs do not download dotenv artifacts by default, causing new trace IDs generated.
How Observability Changed My (Developer) Life is a great read about the expansion of metrics, logs and how traces and spans help tackling the complexity of microservices architectures. It also highlights observability data costs, and the requirement of sampling with the OpenTelemtry collector or Honeycomb Refinery. The article "Monitoring is a Pain" takes a different view, and sheds light into missing helpful standards in logging, the complexity with metrics architectures, and that tracing should be enabled and work OOTB. Great reminder for increased project adoption and contributions.
Julius Volz continued his amazing learning series "Prometheus Monitoring with Julius":
- 7 Things You Didn't Know About Prometheus | Little-Known Features and Implementation Details
- Exposing Custom Host Metrics Using the Prometheus Node Exporter | "textfile" Collector Module
- Understanding Counter Rates and Increases in PromQL | Reset Handling, Extrapolation, Edge Cases
Quick wins:
- If you are managing, or starting to adopt SLOs, Service Level Objectives made easy with Sloth and Pyrra is a great read for better efficiency. Chaos-driven observability: spotting network failures in a Kubernetes cluster
🛡️ DevSecOps¶
After Red Hat announced that the RHEL source code will only be accessible through the Red Hat Customer portal, this led to responses in the community from RHEL binary compatible clones such as RockyLinux and AlmaLinux.
Some additional context: Access to the exact same source RPM versions will be required to provide binary compatible rebuilds. With Red Hat providing a source code copy and build files (.spec files, etc.) in the public CentOS Git repository, automated rebuilds were much easier than years before where one had to download the SRPM files from public FTP mirrors. CentOS historically has been the the open-source distribution compatible with RHEL. Some years ago, Red Hat acquired CentOS, and changed its release process into a rolling release. This allows Red Hat to build RHEL from CentOS Stream, instead of a frozen Fedora upstream version. Community concerns inspired RockyLinux and AlmaLinux to step into the CentOS place. With removing access to RHEL source code, rebuilding becomes harder and it may or may not be legal (lawyers will have to analyze this situation).
The source code access change also breaks software supply chain, especially for security fixes that are developed for or by Red Hat, and may reach the public community later (or too late). This week, Oracle added concerns about compatibility issues with Oracle Linux after 9.2. SuSE went one step further, and announced a fork of the publicly available RHEL sources and planning to invest $10+ million while promising its investments in SuSE Linux Enterprise (SLE). Hopefully folks find a way to collaborate, and drive the open source spirit again.
Quick wins:
- Defending Continuous Integration/Continuous Delivery (CI/CD) Environments - thanks tl;dr sec.
- A curated list of awesome Kubernetes security resources
🌤️ Cloud Native¶
Cost efficiency, and sustainable resource usage, is an important topic. The maintainers of Kepler, a CNCF sandbox project, thought about sustainable environments and power consumption observability for Kubernetes clusters. They started a Prometheus metrics exporter that uses eBPF to probe performance counters and other system stats. The data is processed with ML models to estimate workload energy consumption based on these stats. These projects will help with sustainable computing efforts to reduce CO2 emissions and can also help with pipeline efficiency strategies:
- Kepler (Kubernetes-based Efficient Power Level Exporter) uses eBPF to probe energy-related system stats and exports as Prometheus metrics.
- PEAKS (Power Efficiency Aware Kubernetes Scheduler) uses metrics exported by Kepler to help Kubernetes schedule to improve energy efficiency by placing Pods on optimal nodes.
- CLEVER (Container Level Energy-efficient VPA Recommender) uses metrics exported by Kepler to recommend Vertical Pod Autoscaler the resource profiles to improve energy efficiency by running workloads.
Suggest subscribing to updates and trying the projects in your production environments.
Quick wins:
- Robusta released a new tool to find over/under-provisioned resources in a Kubernetes cluster: krr. It describes itself as Prometheus-based Kubernetes Resource Recommendations.
- Daniele Polencic shared 20 Kubernetes learning threads in 20 weeks - fantastic content to learn new topics, or verify existing knowledge. Daniele also provides more Kubernetes learning content on learnk8s.io.
- Oldschool published a great read about GitLab Runners on Kubernetes, diving into observability and scalability requirements, how they managed to avoid the deprecated docker-machine autoscaling mechanism, how upgrades and rollback do not duplicate worker pools, and debugging strategies for incidents.
- Jan Schürmann shared a KubeShark demo spontaneously at Cloudland 2023, and how they use it in production for analyzing traffic in Kubernetes.
📚 Tools and tips for your daily use¶
- CLI tool to insert spacers when command output stops. This can be helpful for continuous shell output, i.e. running a script in foreground.
- s-tui - Terminal-based CPU stress and monitoring utility. Great tool for simulating slow CI/CD pipelines too.
- The ultimate Vim configuration (vimrc). Plenty of tips inside. My personal .vimrc has been carried over from the first Debian or CentOS based Linux machines to macOS, 10+ years of hidden efficiency.
- Docker Cheat Sheet – 36 Docker CLI Commands
- Popeye - A Kubernetes cluster resource sanitizer - thanks Christian Heckelmann.
- kui - A hybrid command-line/UI development experience for cloud-native development
- Karpenter - Just-in-time Nodes for Any Kubernetes Cluster
- keep is an open-source alerts management platform for developers.
🔖 Book'mark¶
- Awesome Rust Books to learn Rust.
- Quickstart guide for GitLab Remote Development workspaces
- Optimizing SW Adoption and Maintenance: API Compatibility Guarantees with Björn Rabenstein - Optimize all the things podcast.
🎯 Release speed-run¶
Flux v2.0.0 comes with the promotion of the GitOps related APIs to v1 and adds horizontal scaling & sharding capabilities to Flux controllers. The Git bootstrap capabilities provided by the Flux CLI and by Flux Terraform Provider are now considered stable and production ready. Starting with this version, the build, release and provenance portions of the Flux project supply chain provisionally meet SLSA Build Level 3. Flux GA is fully integrated with Kubernetes Workload Identity for AWS, Azure and Google Cloud to facilitate passwordless authentication to OCI sources (container images, OCI artifacts, Helm charts). The Flux alerting capabilities have been extended with PagerDuty and Google Pub/Sub support. The improved Alert v1beta2 API provides better control over events filtering and allows users to enrich the alerts with custom metadata.
Parca v0.20.0 improves support for short-lived processes, adds support for unwinding mixed stacks, and many more performance improvements. Jaeger Tracing v1.47.0 supports Prometheus normalization for OpenTelemetry metrics. Grafana 10 helps visualize real-time dashboards with a new trend panel, while time region support is provided with the canvas panel and time series panel. Dashboards as code got improvements with a revamped version of the Grafonnet library, and a Terraform provider for composing dashboards.
Trivy v0.43.0 adds scanning for development dependencies, skipping services in cloud scanning, and supports Kubernetes bill of materials, Kubernetes private registries, Yarn workspaces. GitLab 16.1 brings a new navigation experience, visualizes Kubernetes resources, service account authentication, job artifact management, and more async CI/CD workflows with needs in rules. Hurl 4.0.0 improves error reporting in CI/CD, adds new filters for decode and xpath, and adds a request waterfall timeline into the HTML reports.
Docker Desktop 4.21 adds support for new Wasm runtimes, including Fermyon Spin. Go 1.21 RC added Wasm and Wasi support (example project).
🎥 Events and CFPs¶
- Jul 17-18: Kubernetes Community Days Munich, in Munich, Germany.
- Aug 9-10: DevOpsDays Chicago 2023 in Chicago, IL.
- Aug 22: Kubernetes Community Days Australia in Sydney, Australia.
- Sep 11-13: Container Days EU 2023 in Hamburg, Germany. See you there!
- Sep 13: eBPF Summit 2023, online.
- Sep 26-27: Kubernetes Community Days Austria in Vienna, Austria.
- Oct 2-6: DEVOXX Belgium, Antwerp, Belgium.
- Oct 6-7: DevOps Camp Nuremberg, Nuremberg, Germany. See you there!
- Oct 10-12: SRECON EMEA in Dublin, Ireland.
- Oct 17-18: Kubernetes Community Days UK in London, UK.
- Nov 6-9: KubeCon NA 2023, Chicago, IL. Planning to be there.
- Nov 6: Observability Day at KubeCon NA 2023, Chicago, IL.
- Nov 6: CiliumCon at KubeCon NA 2023, Chicago, IL.
- Nov 6: AppDeveloperCon at KubeCon NA 2023, Chicago, IL.
- Nov 16-17: Continuous Lifecycle / Container Conf in Mannheim, Germany.
👋 CFPs due soon
- Sep 13: eBPF Summit 2023, online. CFP closes Jul 21.
- Sep 26-27: Kubernetes Community Days Austria in Vienna, Austria. CFP closes Jul 30.
- Nov 6: Observability Day at KubeCon NA 2023, CiliumCon at KubeCon NA 2023, AppDeveloperCon at KubeCon NA 2023 and more co-located events in Chicago, IL. CFP closes Aug 6.
Looking for more CfPs?
- CFP Land.
- Developers Conferences Agenda by Aurélie Vache.
- Kube Events.
- GitLab Speaking Resources handbook.
🎤 Shoutouts¶
Julia Evans for creating a fun exercise to implement DNS in a weekend.
🌐
Thanks for reading! If you are viewing the website archive, make sure to subscribe to stay in the loop!
See you next month - let me know what you think on LinkedIn, Twitter, Mastodon.
Cheers,
Michael
PS: If you want to share items for the next newsletter, please check out the contributing guide - tag me in the comments, send me a DM or submit this form. Thanks!